 GB
GBIT Infrastructure & Data Protection Expert
Dans notre dernier blog ELK, nous avons configuré ELK (Elasticsearch, Logstash et Kibana) sur Docker. Maintenant, nous allons transformer ces journaux complexes en éléments de base qui vous permettront de créer des visualisations dans Kibana.
Si vous n'avez pas encore lu Pratique Pratique avec la pile ELK, vous pouvez commencer par cloner le dépôt GitHub suivant pour configurer votre pile ELK : https://github.com/object1st/elk-stack.git
cd elk-stack
commande d'exécution :
docker-compose up -dEnsuite, naviguez vers votre navigateur à l'adresse IP ou au nom DNS de votre VM (ou hôte local si vous faites cela localement) et sur le port 5601, accédez à Kibana : http://myvm:5601
Analyse de Syslog
À la fin de cette démonstration, vous pouvez vous attendre à avoir :
- Analysé un message syslog complexe
- Créé une détection de menaces intelligente qui repère automatiquement un indicateur de ransomware
- Construit un tableau de bord pour afficher l'alerte
Le défi : Structures de journaux complexes
Commençons par un message syslog du monde réel.
Exemple : Veeam Détection de Malware
Mar 20, 2025 @ 14:06:09.662 VBRSRV01 Veeam_MP: [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="TECH\user1" ObjectName="VM01" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected for OIB: 0e54d3bf-add8-48eb-9122-fad3ac1e8fb3 (VM01), rule: Encrypted data by user: TECH\user1."]Pourquoi ces messages sont importants
Vous trouverez des informations précieuses dans ce message journal - prenez un moment pour l'explorer.
Veeam message :
- Activité potentielle de ransomware en cours
- Compte utilisateur spécifique impliqué (TECH\user1)
- Machine virtuelle affectée (VM01)
- Modèle comportemental (activité de données chiffrées)
Mais dans son état actuel, vous ne pouvez pas facilement :
- Suivre quelles VM sont potentiellement affectées.
- Corréler l'activité suspecte dans le temps
- Générer des rapports sur cette activité
Étape 1 : Commencer Simple, Construire Intelligent
Voici où la plupart des gens se trompent : essayer d'analyser tout en même temps et finir avec une configuration qui ne fonctionne pas.
Si vous souhaitez suivre, localisez les fichiers dans le dossier “Exemples” du dépôt GitHub. Si vous avez déjà installé ELK dans Docker à partir de l'article de blog précédent, copiez simplement ces fichiers dans votre configuration. Au fur et à mesure que vous travaillez à travers ce blog, remplacez les fichiers existants par les versions mises à jour fournies ici. Si vous faites une erreur ou vous perdez en cours de route, vous pouvez toujours re-cloner le dépôt pour repartir de zéro.
- Pour utiliser, supprimez le logstash.conf dans le pipeline en le remplaçant par
logstash_version1.conf ($ cp ~/elk-stack/Examples/logstash_version1.conf ~/elk-stack/logstash/pipeline/logstash.conf) - Redémarrez le conteneur logstash ($ docker-compose restart logstash).
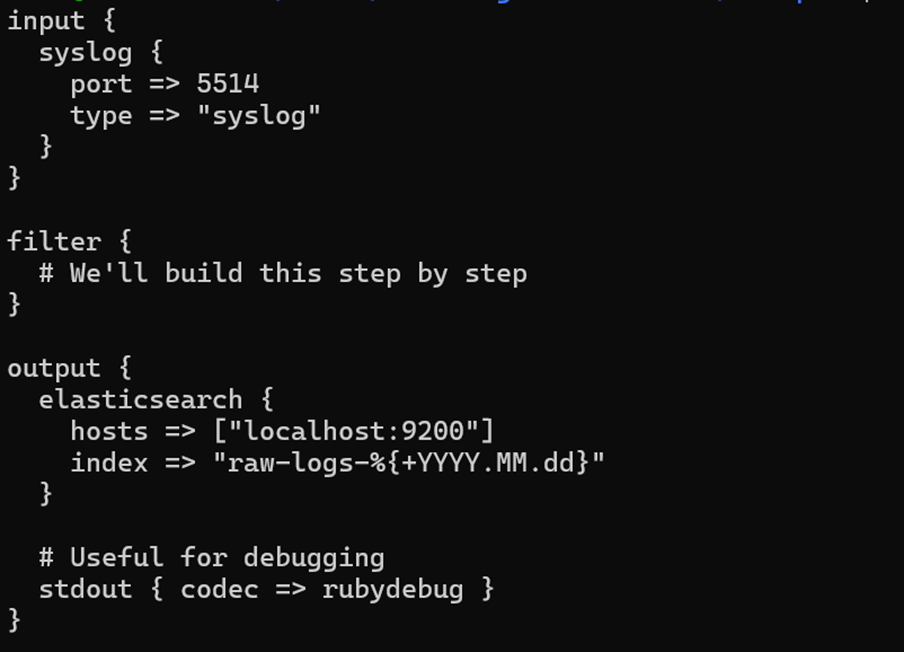
Pourquoi cette approche fonctionne :
- Commencer avec une entrée/sortie fonctionnelle
- Utiliser stdout pour voir exactement ce que Logstash reçoit (s'affichera dans les journaux du conteneur docker)
- Les journaux bruts vont toujours vers Elasticsearch (rien n'est perdu)
- Construire la complexité progressivement sans casser les choses
Étape 2 : Testez votre configuration
- Envoyez vos messages d'exemple à Logstash et observez la sortie. Voici quelques méthodes que vous pouvez utiliser pour envoyer un message syslog vous-même.
- En utilisant netcat :
- Copiez et collez la commande suivante dans votre CLI (Veeam Message Syslog) :
echo '<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="TECH\user1" ObjectName="VM01" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected"]' | nc -u -q0 localhost 5514- Vous devriez voir quelque chose comme ceci lorsque vous tapez docker logs logstash :
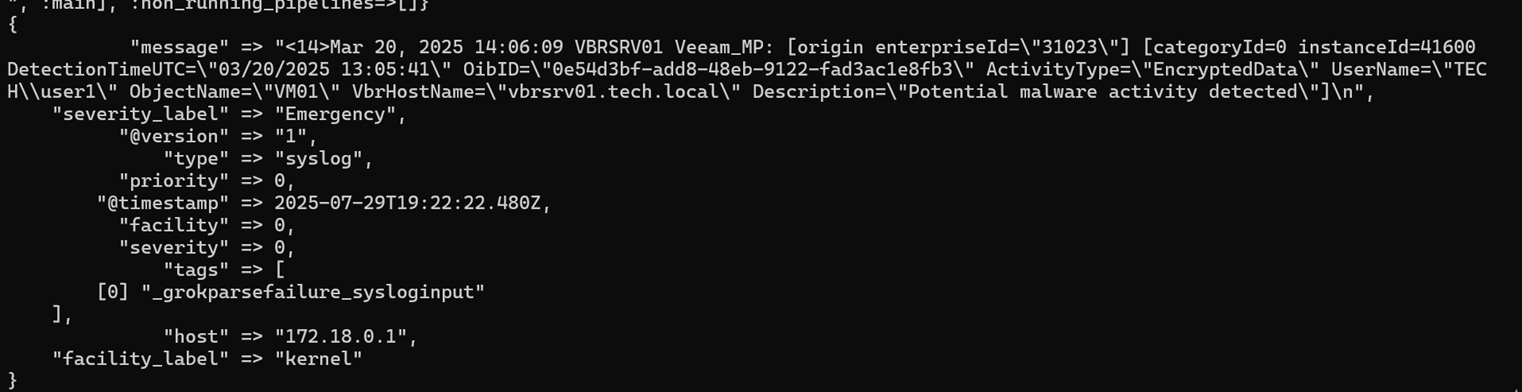
C'est un problème car tout ce qui est précieux est piégé dans un seul champ de message géant :
“"message" => "<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId=\"31023\"] [categoryId=0 instanceId=41600 DetectionTimeUTC=\"03/20/2025 13:05:41\" OibID=\"0e54d3bf-add8-48eb-9122-fad3ac1e8fb3\" ActivityType=\"EncryptedData\" UserName=\"TECH\\user1\" ObjectName=\"VM01\" VbrHostName=\"vbrsrv01.tech.local\" Description=\"Potential malware activity detected\"]\n",”Pour résoudre ce problème, analysez les journaux pour les rendre plus clairs.
Voici où les choses deviennent intéressantes (et légèrement terrifiantes si vous êtes nouveau dans les regex). Nous allons disséquer ce journal et le rendre plus facile à extraire des morceaux d'information.
Avant d'écrire du code, comprenons avec quoi nous travaillons :
Veeam Structure : [timestamp] [hostname] [application] : [origin_data] [detection_data]
Étape 3 : Analyse de base
Copiez le fichier logstash suivant :
1. Pour utiliser, supprimez le logstash.conf dans le pipeline en le remplaçant par logstash_version2.conf ($
cp ~/elk-stack/Examples/logstash_version2.conf ~/elk-stack/logstash/pipeline/logstash.conf) 2. Redémarrez le conteneur logstash ($ docker-compose restart logstash)
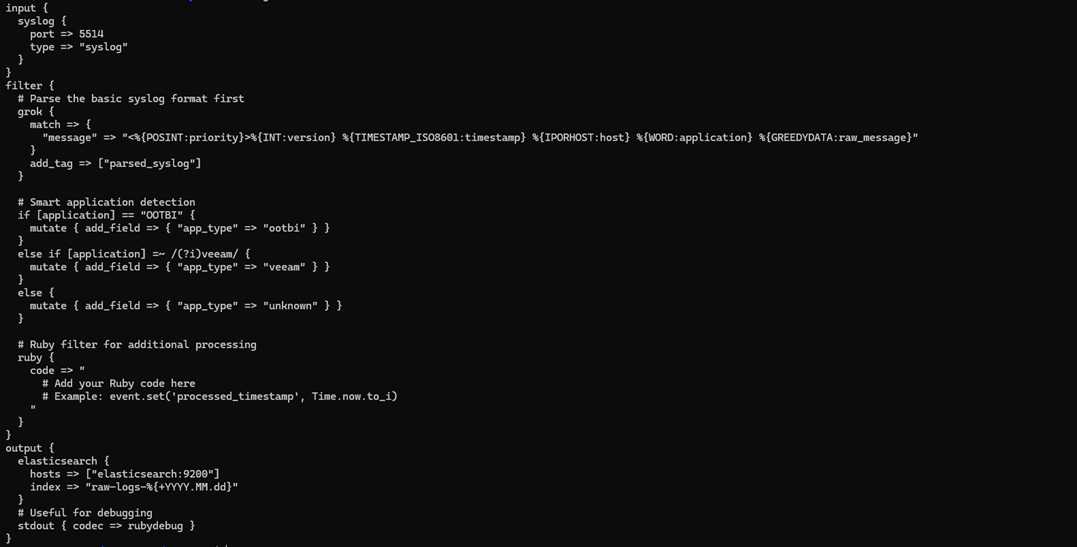
Modèle Grok décodé :
- %{POSINT:priority} → Capture des entiers positifs comme "priority"
- %{TIMESTAMP_ISO8601:timestamp} → Modèle intégré pour les horodatages ISO
- %{IPORHOST:host} → Adresse IP ou nom d'hôte
- %{GREEDYDATA:raw_message} → Tout le reste (nous allons analyser cela ensuite)
Ce nouveau modèle Grok est conçu pour décomposer les messages syslog bruts en données structurées et exploitables. Plus précisément, il sépare les composants de base d'un message syslog (comme l'horodatage, le nom d'hôte et le niveau de journal), identifie la source de l'application générant le journal et étiquette chaque message pour un traitement ultérieur dans le pipeline. Cette étape fondamentale permet une analyse, un enrichissement et une logique d'alerte plus avancés plus tard dans le flux de travail.
3. Testez à nouveau pour voir les différences :
echo '<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="TECH\user1" ObjectName="VM01" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected"]' | nc -u -q0 localhost 55144. Ensuite, vérifiez les journaux du conteneur logstash ($ docker logs logstash).
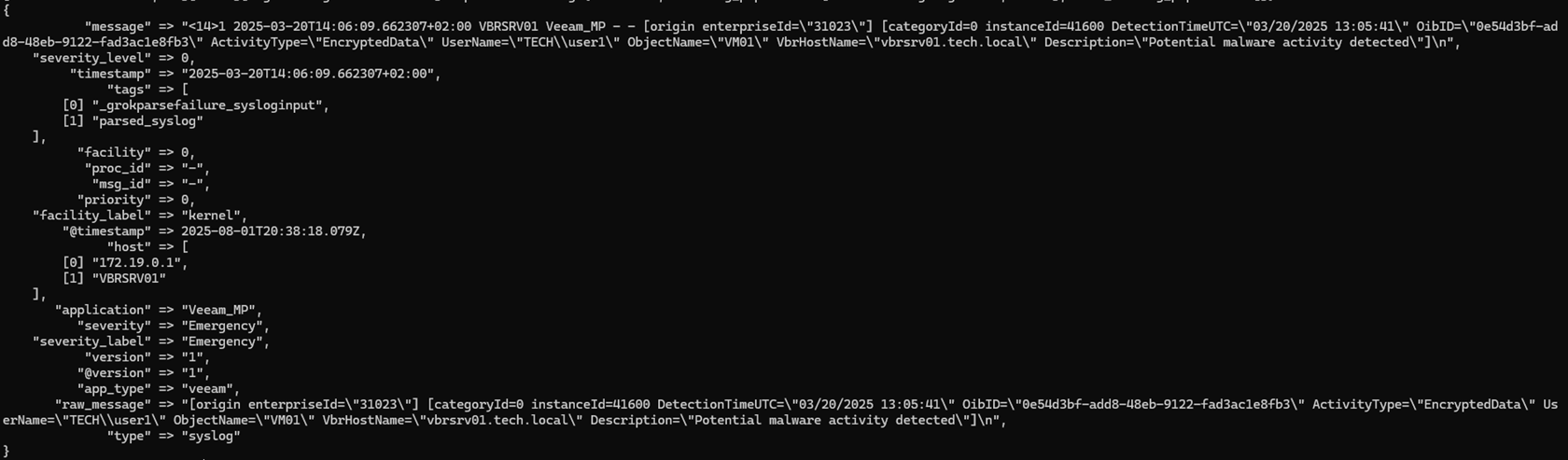
Les champs que nous avons extraits :
priority → 0
timestamp → 2025-03-20T14:06:09.662307+02:00
host → ["172.19.0.1", "VBRSRV01"]
application → "Veeam_MP"
severity → "Urgent"
severity_level → 0
Étape 4 : Plongée plus profonde dans l'analyse
Nous allons maintenant faire encore plus d'analyses. Le fichier est trop grand pour être imprimé ici, mais il se trouve dans votre dossier “Exemples” sous logstash_version3.conf.
- Pour utiliser, supprimez le logstash.conf dans le pipeline en le remplaçant par : logstash_version3.conf ($
cp ~/elk-stack/Examples/logstash_version3.conf ~/elk-stack/logstash/pipeline/logstash.conf) - Redémarrez le conteneur logstash ($ docker-compose restart logstash).
- À ce stade, testez votre configuration. Vous devriez voir des champs individuels au lieu d'un gros blob de message.
- Exécutez à nouveau le même message de test, puis vérifiez les journaux du conteneur logstash ($ docker logs logstash).
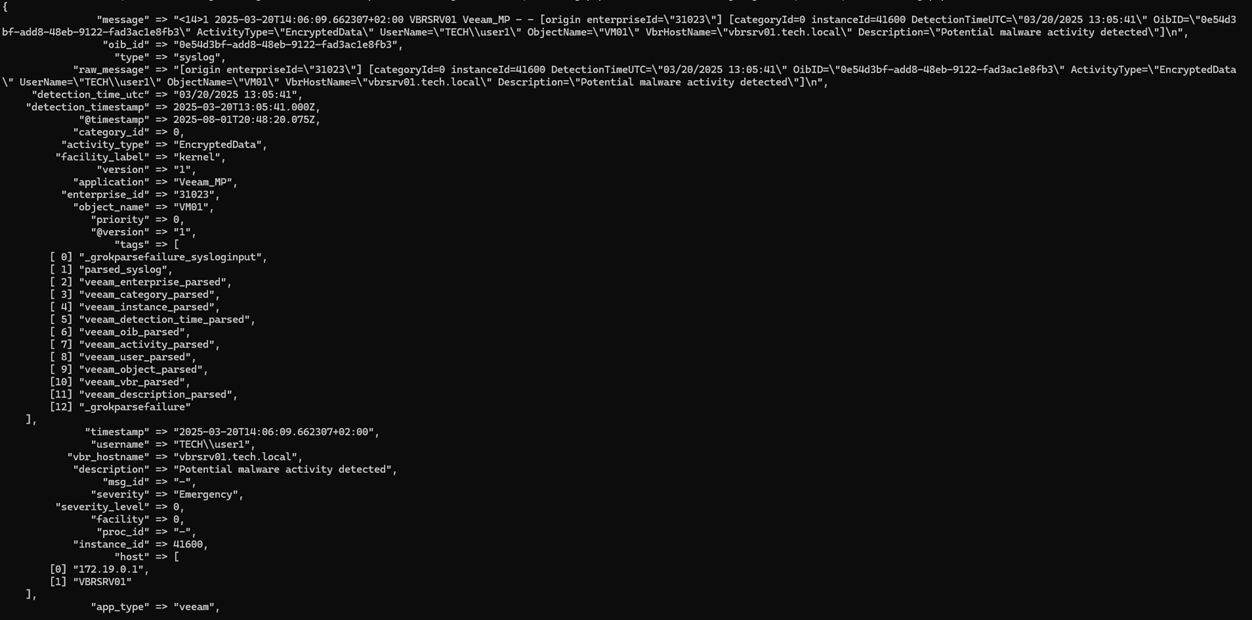
Les champs que nous avons extraits :
enterprise_id → "31023"
category_id → 0 (converti en entier)
instance_id → 41600 (converti en entier)
detection_time_utc → "03/20/2025 13:05:41"
detection_timestamp → 2025-03-20T13:05:41.000Z (horodatage correctement analysé)
oib_id → "0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" (ID d'alerte unique)
activity_type → "EncryptedData" (indicateur de malware)
username → "TECH\\user1"
object_name → "VM01" (VM affectée)
vbr_hostname → "vbrsrv01.tech.local"
description → "Activité potentielle de malware détectée"
Étape 5 : Veeam Renseignement sur les menaces et gestion des erreurs
Dernier point mais non le moindre, nous devons ajouter de l'intelligence à notre système et gérer les erreurs pour nous aider à déboguer si nécessaire. Ajouter de l'intelligence est important car cela permet de filtrer par impact commercial, autorise des alertes basées sur la priorité, rend la création de tableaux de bord intuitive, fournit des recommandations exploitables et réduit la fatigue des alertes.
Voici comment ajouter de l'intelligence et gérer les erreurs :
- Pour utiliser, supprimez le logstash.conf dans le pipeline en le remplaçant par : logstash_version4.conf ($
cp ~/elk-stack/Examples/logstash_version4.conf ~/elk-stack/logstash/pipeline/logstash.conf) - Redémarrez le conteneur logstash ($ docker-compose restart logstash).
- Attendez que le pipeline soit en cours d'exécution, puis envoyez à nouveau le message de test :
echo '<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="TECH\user1" ObjectName="VM01" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected"]' | nc -u -q0 localhost 5514Quels nouveaux champs avons-nous extraits :
threat_type → "potential_ransomware" (catégorisation intelligente des menaces)
event_category → "malware" (classification de sécurité)
business_impact → "high" (évaluation des risques)
alert_priority → "critical" (priorité d'escalade)
recommendation → "Enquête immédiate requise" (guidance de réponse)
event_type → "security_event" (classification des événements)
Résumé de la section
Dans cette section, nous avons réussi à accomplir ce qui suit :
- Ajouté un contexte commercial aux événements bruts
- Créé une classification de gravité intelligente
- Construit un système de catégorisation des menaces
- Activé des alertes basées sur la priorité
Étape 6 : Créer un modèle d'index
Avant de commencer à envoyer des données dans Elasticsearch, nous devons l'optimiser pour notre cas d'utilisation spécifique.
1. Dans le dépôt GitHub, vous trouverez le fichier index_template.json, que nous pouvons importer dans Kibana.
2. Utilisons une commande curl pour importer notre index_template.json depuis le dossier "Exemples".
Si vous avez des difficultés à copier les commandes ici, vous pouvez également les trouver dans le fichier README.md du dépôt github
curl -X PUT "localhost:9200/_index_template/veeam-syslog-template" \ -H "Content-Type: application/json" \ -d @index_template.json3. Vous devriez voir ce message si l'importation a réussi.
4. Ensuite, nous allons créer un modèle d'index (dans les versions ultérieures appelé Vues de données).
- Tapez la commande suivante :
curl -X POST "localhost:5601/api/saved_objects/index-pattern/syslog-pattern" -H "Content-Type: application/json" -H "kbn-xsrf: true" -d '{"attributes":{"title":"syslog-*","timeFieldName":"@timestamp"}}'- Vous pouvez également créer via l'interface Web.
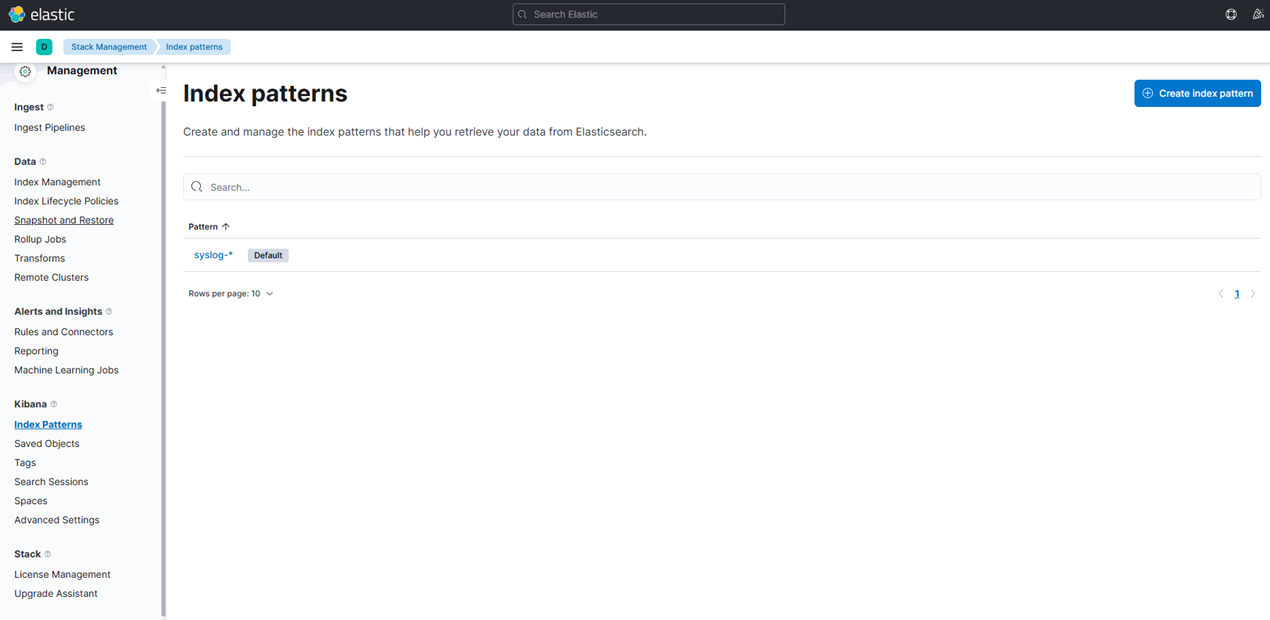
5. Vérifiez si le modèle d'index a été créé en prenant les actions suivantes :
- Allez dans la gestion de la pile
- Cliquez sur "Modèles d'index" sous "Kibana"
- Ici, nous pouvons voir notre modèle d'index nouvellement créé.
6. Ensuite, nous devons créer une visualisation.
- Cliquez sur "Bibliothèque de visualisation."
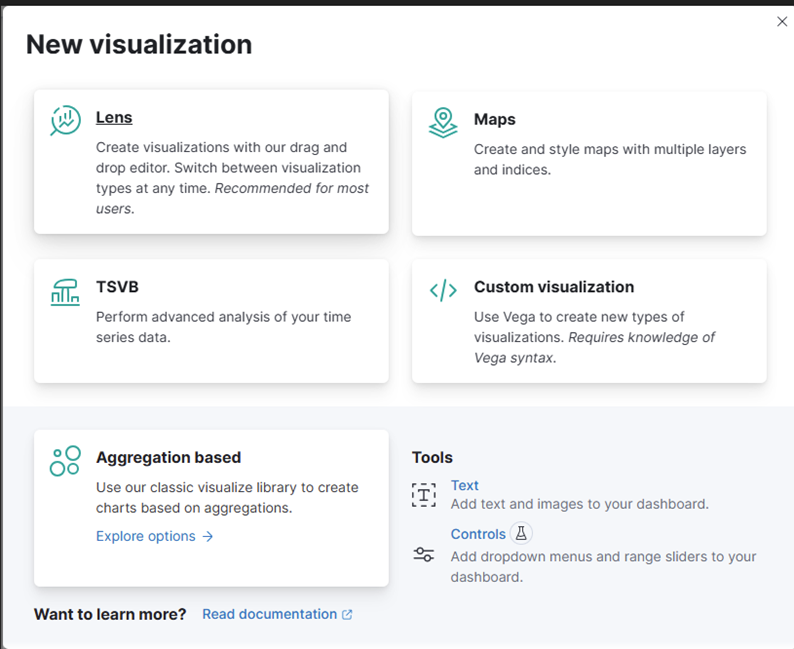
- Cliquez sur le bloc "Lens".
- Dans le menu déroulant, choisissez "Métrique."
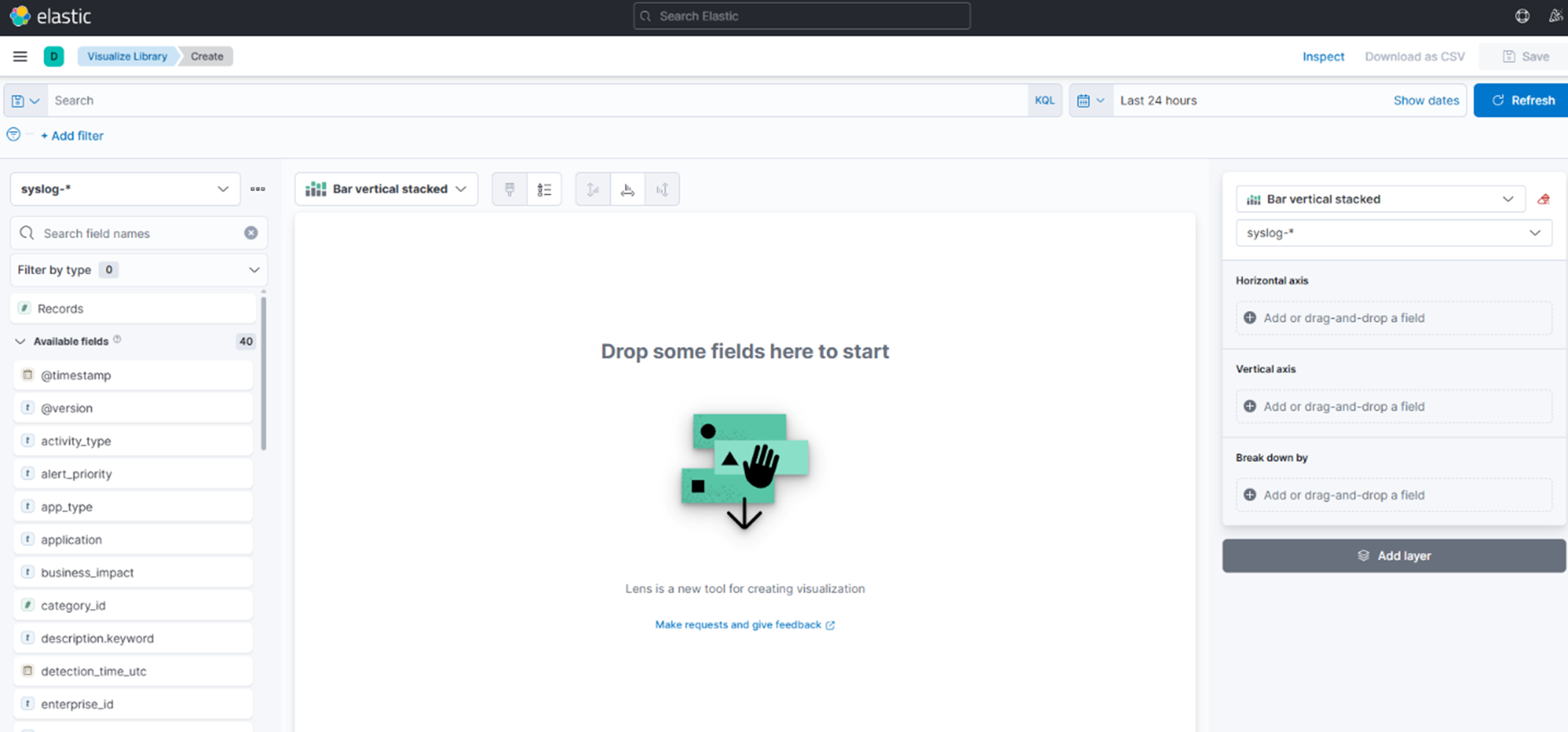
7. Dans le champ de filtre, tapez : threat_type : "potential_ransomware"
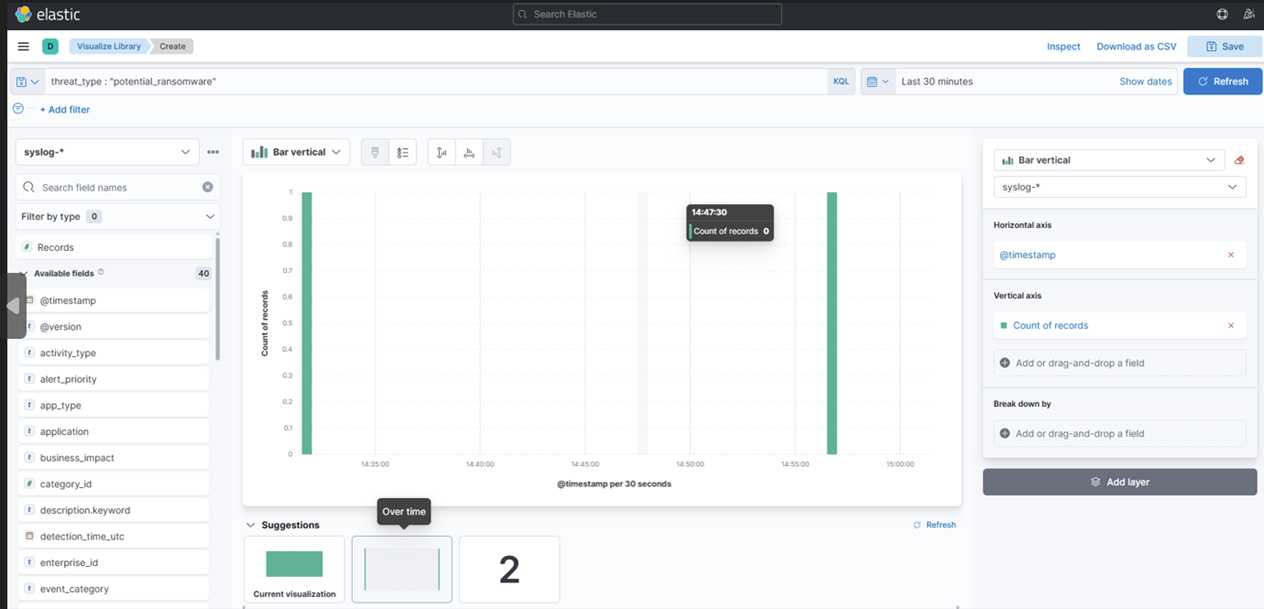
8. Choisissez "Overtime" au milieu (c'est votre choix de ce à quoi vous voulez que le tableau de bord ressemble).
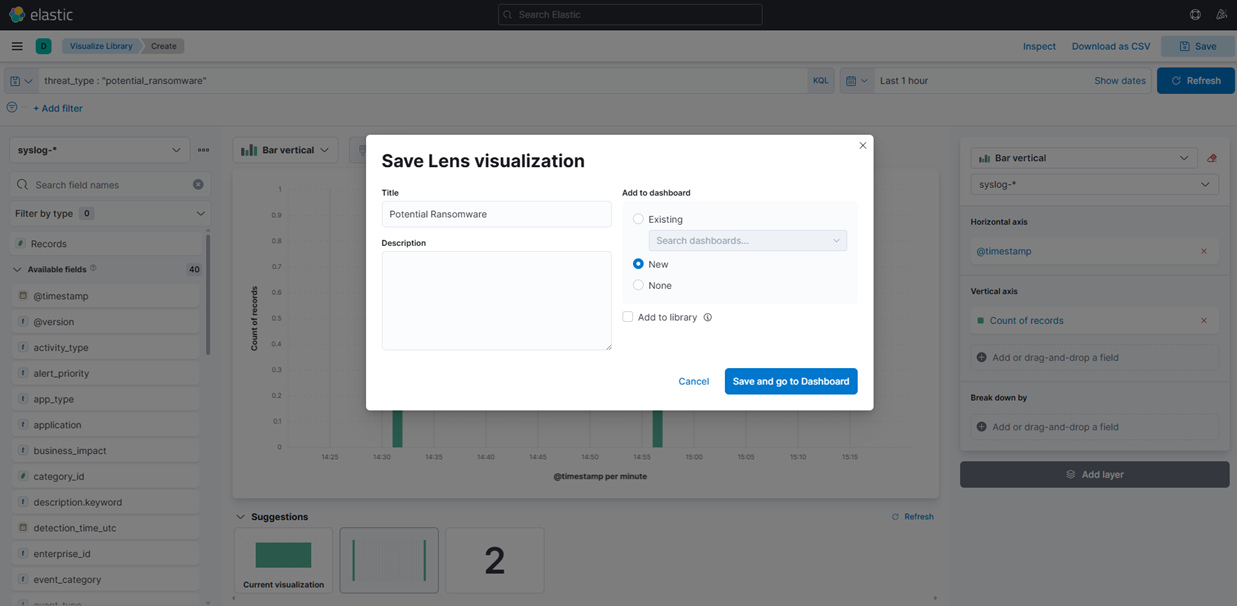
9. Enregistrez la visualisation en cliquant sur le bouton "Enregistrer" dans le coin supérieur droit et ajoutez-la à un nouveau tableau de bord :
10. Changez le "Nom" sous Métriques en "Alertes" et choisissez Enregistrements à gauche.
- Vous devriez finir avec ceci :
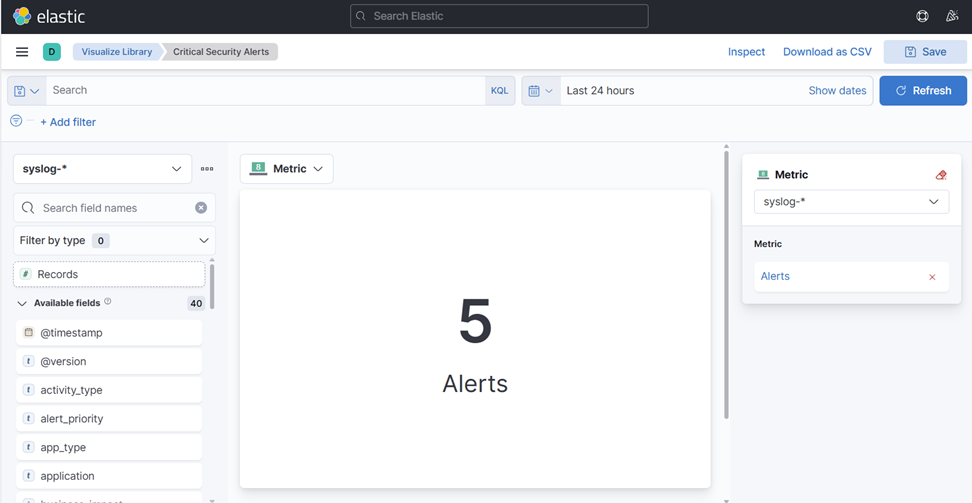
11. Enregistrez ceci dans votre bibliothèque de visualisation et choisissez "Pas de tableau de bord" pour l'instant.
12. Ensuite, créez une autre visualisation que nous appellerons "Machines affectées."
- Cette fois, choisissez Table, pas Métrique, et utilisez le champ "Top values of object_name" et enregistrez à nouveau. Changez les noms des colonnes en appuyant sur les noms du côté droit et en changeant le nom d'affichage :
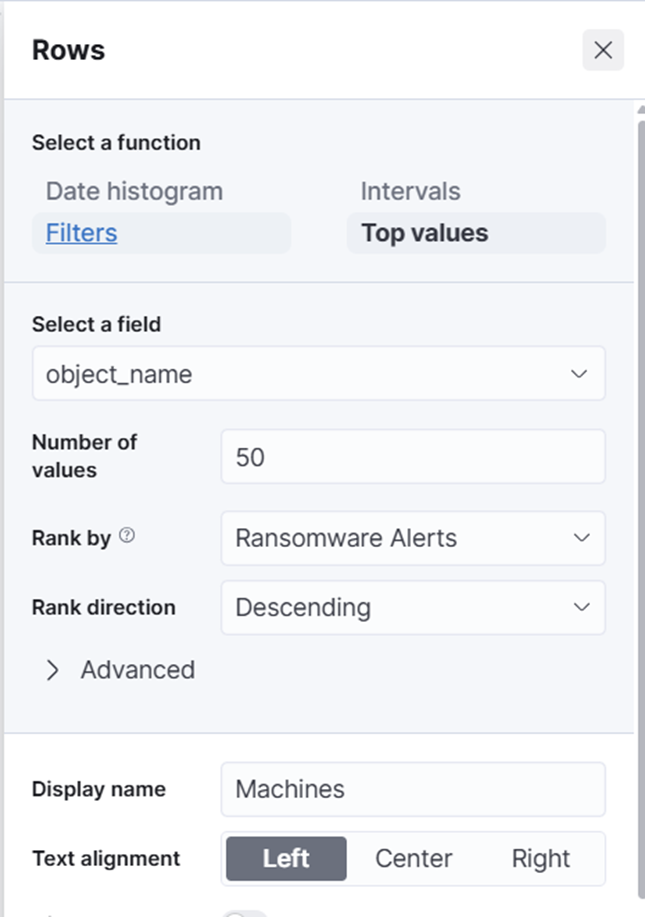
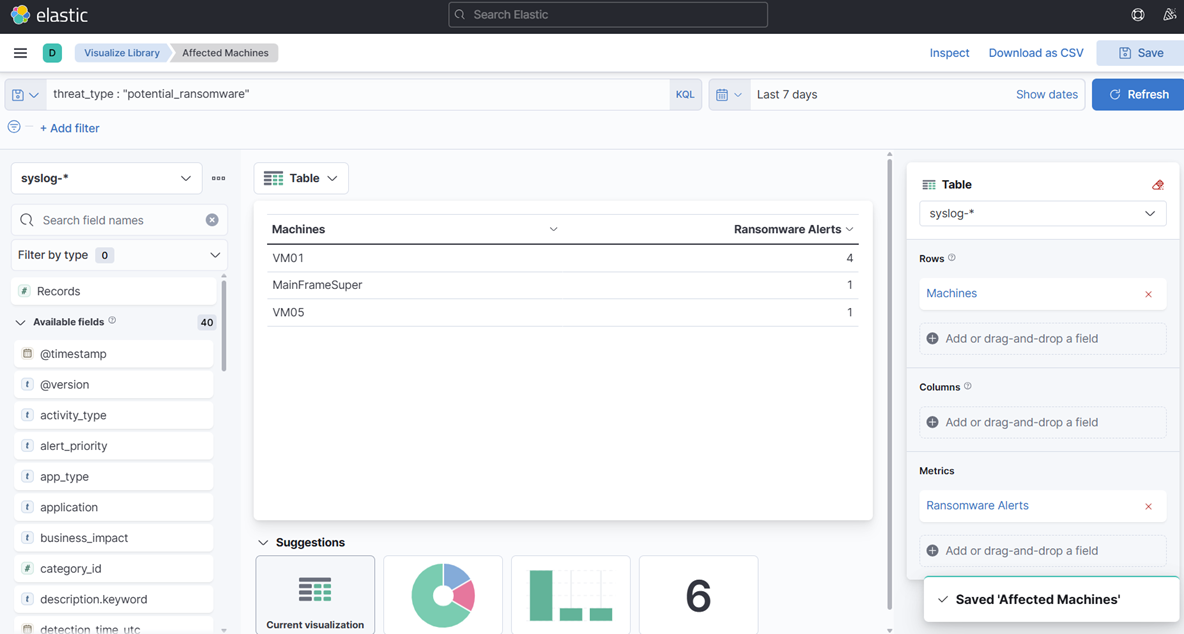
13. Enregistrez à nouveau dans votre bibliothèque.
14. Maintenant, créons une autre visualisation de tableau—cette fois en utilisant le champ "Top Values of Username". Cela peut aider à identifier quels utilisateurs ont pu être connectés pendant l'attaque. Gardez à l'esprit que c'est purement à des fins exploratoires et démontre à quel point vous pouvez exploiter les données de manière créative.
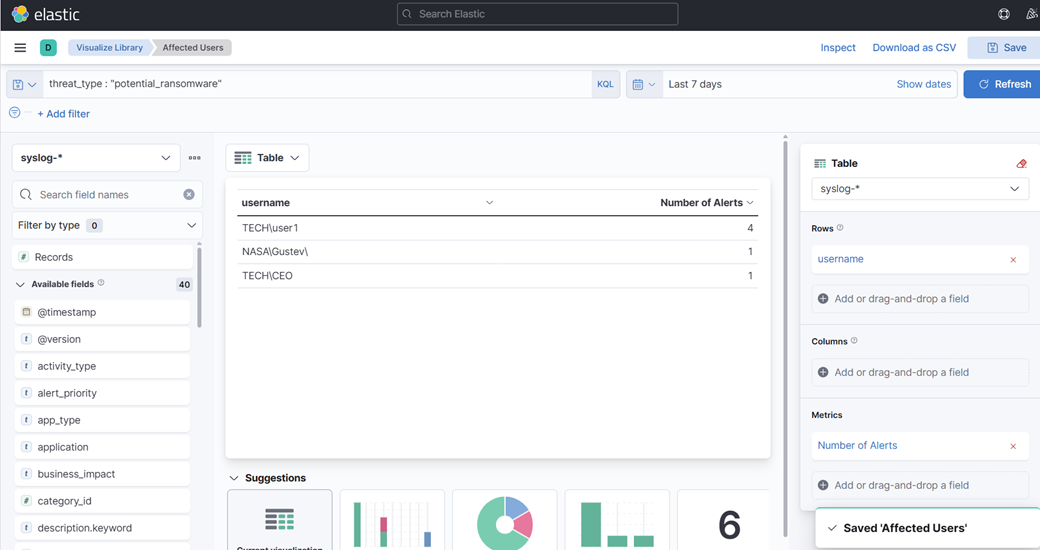
15. Enfin, créez une visualisation de zone—cette fois montrant des alertes et des chronologies.
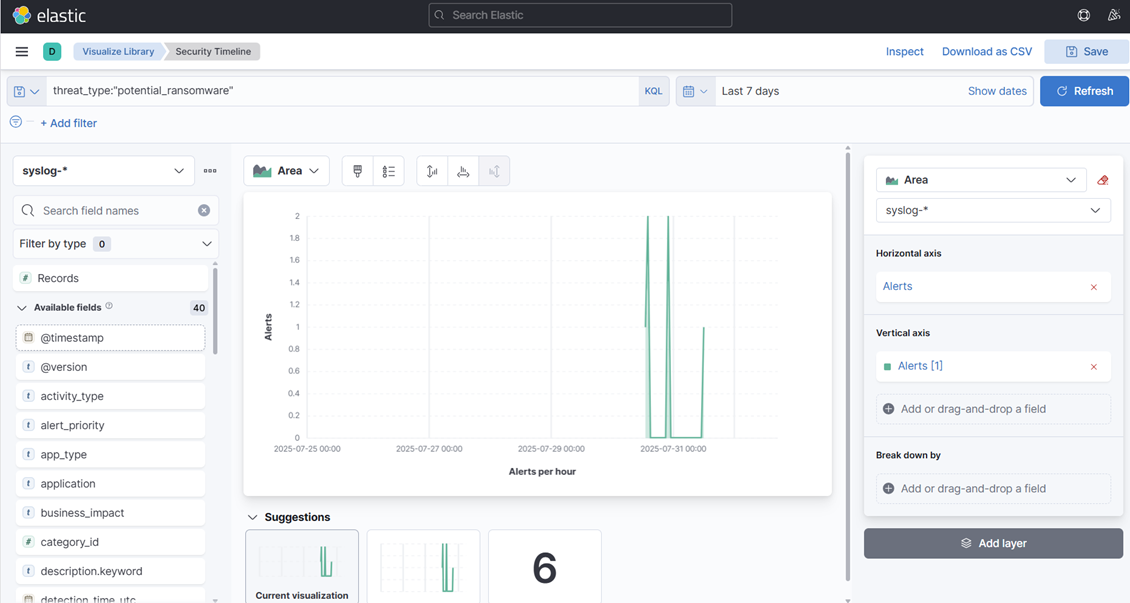
16. N'hésitez pas à créer plus ou à modifier les existantes afin de vous familiariser avec cela. Nous avons créé quelques visualisations très basiques juste pour expliquer le processus.
17. Enfin, créez un tableau de bord et ajoutez ces visualisations.
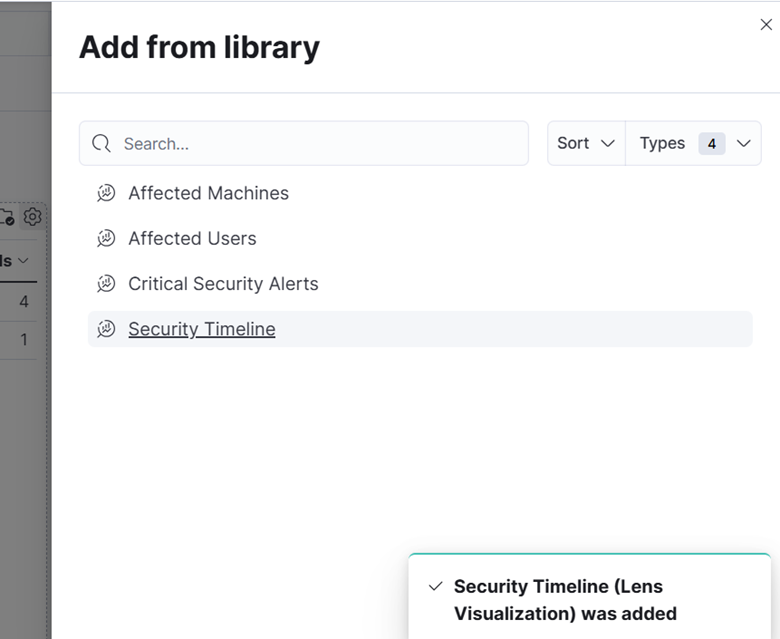
18. Enregistrez le tableau de bord avec le nom "Ransomware potentiel."
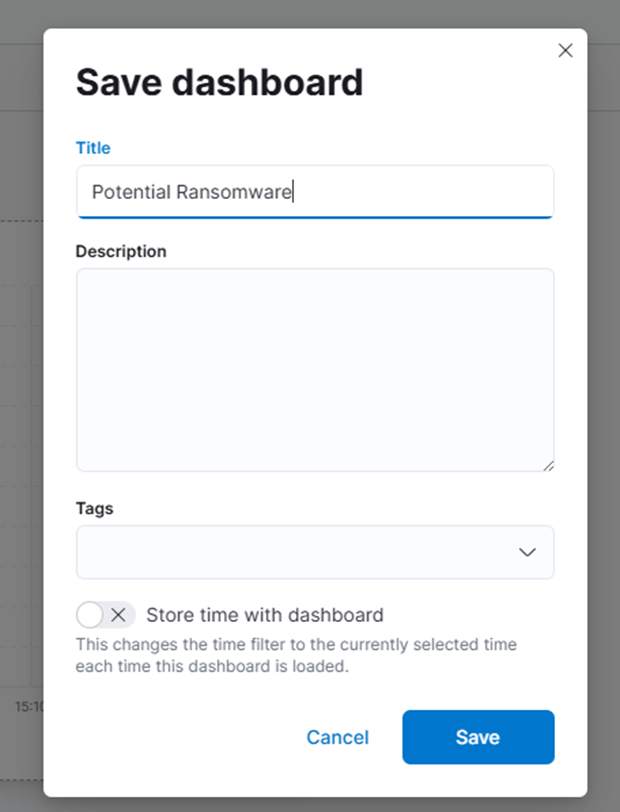
19. Pour tester, envoyons une autre alerte comme si elle provenait de Veeam mais changeons certains des composants du message afin que nous puissions voir si elle est ingérée correctement.
20. Changeons le nom d'utilisateur en Gustev et la VM en MainFrameSuper.
echo '<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="NASA\Gustev\" ObjectName="MainFrameSuper" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected"]' | nc -u -q0 localhost 5514
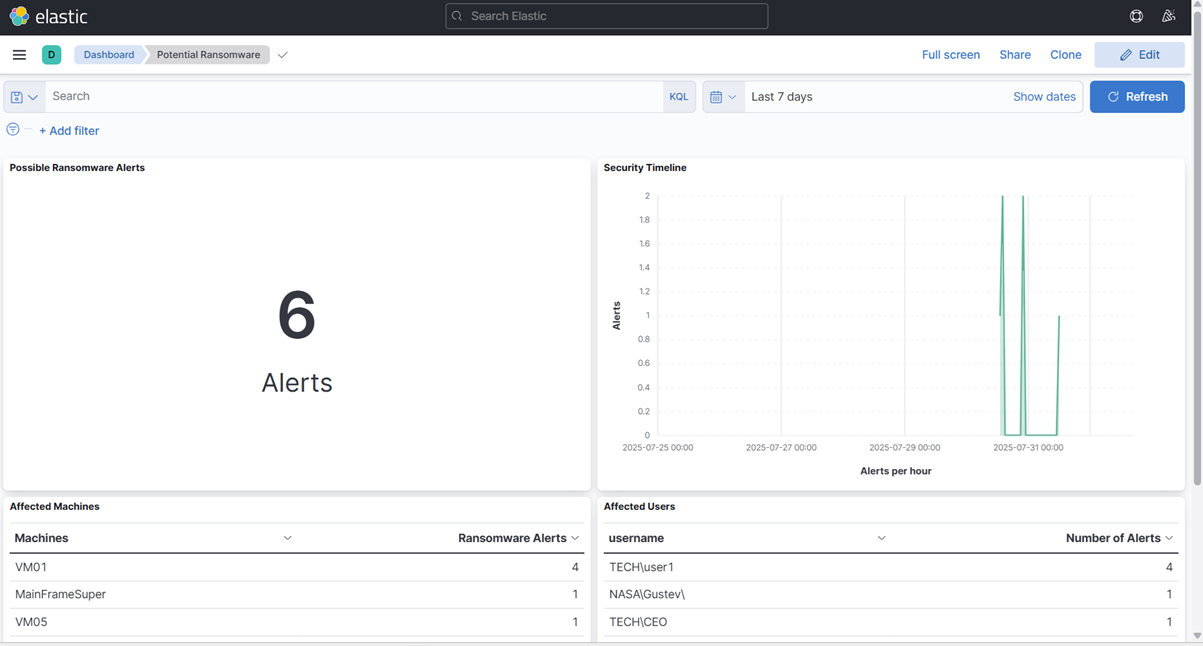
- Comme nous pouvons le voir, notre tableau de bord nous alerte immédiatement dès la réception du message syslog :
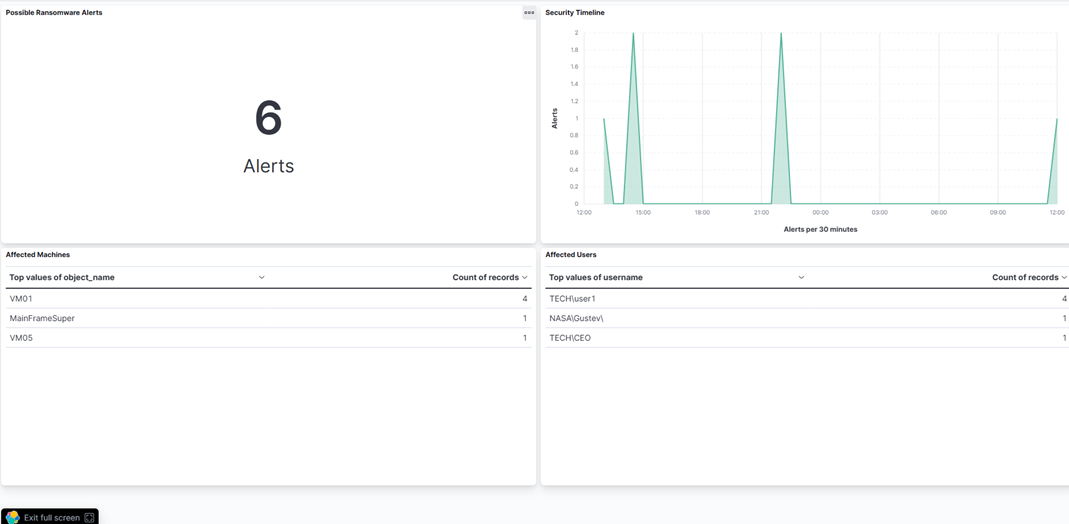
Conclusion
Lorsque vous avez commencé cette série, vous avez été confronté à un mur de texte cryptique de 347 caractères :
<14>1 2025-03-20T14:06:09.662307+02:00 VBRSRV01 Veeam_MP - - [origin enterpriseId="31023"] [categoryId=0 instanceId=41600 DetectionTimeUTC="03/20/2025 13:05:41" OibID="0e54d3bf-add8-48eb-9122-fad3ac1e8fb3" ActivityType="EncryptedData" UserName="TECH\user1" ObjectName="VM01" VbrHostName="vbrsrv01.tech.local" Description="Potential malware activity detected"]Maintenant, ce même message déclenche un système de surveillance de sécurité intelligent qui identifie immédiatement :
- Type de menace : Activité potentielle de ransomware
- Niveau de priorité : Impact commercial critique
- Utilisateur affecté : TECH\user1 (identifié comme humain, pas compte de service)
- Actif compromis : Machine virtuelle VM01
Dans ce blog, nous avons donné aux lecteurs une image plus claire de ce qui doit se passer pour qu'un message syslog brut puisse être utile dans un SIEM—spécifiquement au sein de la pile ELK. De l'analyse à l'enrichissement, nous avons décomposé les étapes essentielles qui transforment des journaux bruyants en informations exploitables.
Dans la prochaine et dernière partie de notre mini-série de blogs sur SIEM Elasticsearch, nous passerons brièvement en revue l'utilisation de Fluentd au lieu de Logstash et aborderons Elastic Security.